Research Projects
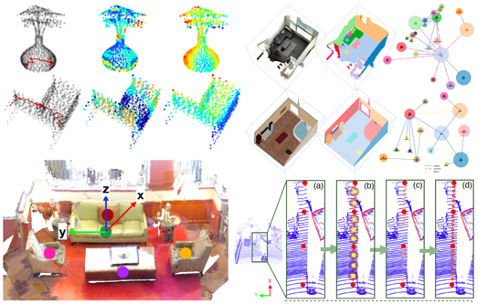
3D Point Cloud Processing and Analysis
Project Leader: A/Prof. Weidong (Tom) Cai
Point cloud is a principal data structure for 3D geometric representation learning. Unlike other conventional visual data, such as images and videos, these irregular points describe the complex shape features of 3D objects or scenes, which are intrinsically close to the essence of 3D computer vision. With recent progress in deep learning, from micro to macro, a growing interest has been rapidly accumulated within the community to promote and facilitate a line of cutting-edge research studies, including (1) designing advanced point cloud processing frameworks for effective 3D object classification and segmentation, (2) establishing more comprehensive object-centric understandings for efficient 3D point cloud analysis, and, (3) shedding lights on a bunch of creative AI-enlightened indoor/outdoor scene-oriented applications such as interior decoration designing and self-driving automobile. Our primary research interests include: 3D point-based scene understanding; Point-wise information propagation and processing; Learning rotation-invariance in point cloud data; Medical point cloud analysis for disease detection and treatment; Audio-visual navigation in complex 3D environments for multimedia computing.
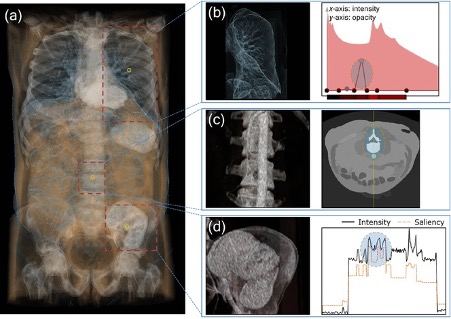
Biomedical Mixed Reality Visualisation
Project Leader: Prof. Jinman Kim
The next generation of medical imaging scanners are introducing new diagnostic capabilities that improve patient care. These medical images are multi-dimensional (3D), multi-modality (fusion of PET and MRI for example) and also time varying (that is, 3D volumes taken over multiple time points and functional MRI). Our research innovates in coupling visualization technologies, including hardware innovation such as Mixed Reality headsets, with AI algorithms to render realistic and detailed 3D representation of the body. Our recent works include generating medical image volume rendering from single image slices and RIbMR that uses HoloLens2 to augment fractured rib bones to the patient’s body during surgery.

Cognition-Inspired Ontology-Guided Image Content Understanding
Project Leader: A/Prof. Xiuying Wang
While we have witnessed rapid development and wide use of DNN in different areas, by far, human cognition is yet to be properly incorporated for deep learning model design. We focus on innovative design of deep learning models to resemble human cognition for saliency detection, the initial research on mimicking human cognitive thinking of images and our approach outperformed 17 benchmarking DNN methods on six well-recognized datasets. To further this cognition-inspired research, our current research is focusing on ontology-guided scene graph generation for image content understanding. In our research, ontology is extracted from Large Language Models (LLMs) and fuse with imagens from image representation learning. This ongoing research effort is to innovate image content understanding for diverse applications.
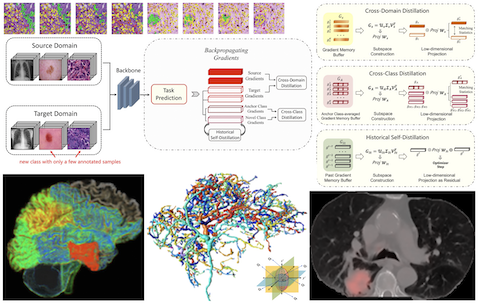
Cross-domain Medical Image Analysis and Processing
Project Leader: A/Prof. Weidong (Tom) Cai
Medical image analysis / processing is an essential step for AI-enhanced diseases diagnosis. With the success of deep learning, recent deep neural network-based methods are now prevalent in medical image segmentation and bio-anomaly detection. Although these fully supervised methods achieve state-of-the-art performance, their high accuracy heavily relies on massively annotated training images from the specific domains. When tested these off-the-shelf models on the images from new unseen domains, the performance suffers from a significant drop. On the other hand, it is impractical to acquire sufficient annotations for each new data source, since the labelling process for computer vision tasks on complex medical imaging data is time-consuming, labour-intensive, and error-prone. This project aims to study enhancing the generalization abilities of current AI models, and to develop novel frameworks for cross-domain medical image analysis and processing.

Human Behavior Understanding
Project Leader: Prof. Zhiyong Wang
Understanding each individual in our society is a fundamental social function for human beings. This project aims to develop cutting edge deep learning techniques for understanding human behavior in both physical and digital world, such as human action understanding, affective state analysis, social interactions in social media platforms, and purchase activities in eCommerce platforms. Expected outcomes of this project should provide significant benefits to a wide range of domains, such as health, sports, social media, and digital retailer.
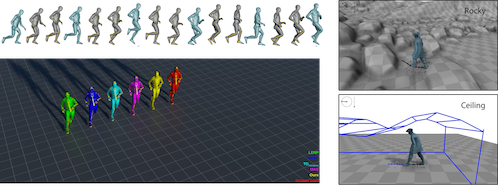
Multimedia Content Creation
Project Leader: Prof. Zhiyong Wang
Recent success of deep learning has demonstrated a great potential to create media content, such as generating human motion. This has opened a new door for creativity and innovation in many domains, such as media, film, and game, even metaverse. This project aims to address the technical challenges of creating highly realistic media content by developing novel computing techniques, such as audio/image/video generation and editing, motion retargeting, 3D animation, cross-modal simulation, and 3D physical simulation. Students will gain comprehensive knowledge in multimedia data processing, computer vision, 3D vision, computer graphics, and machine learning.
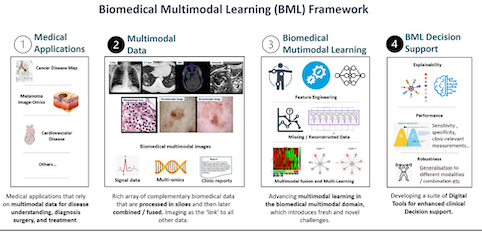
Multi-modal and Cross-modal Learning for Biomedical Image-omics
Project Leader: Prof. Jinman Kim
Clinical imaging is ubiquitous in modern medicine for the evaluation of serious medical conditions. These methods are often used in isolation, despite the rich complementary data sources – such as biological assays – that typically accompany imaging. This project aims to develop an automated machine learning pipeline that augments primary imaging data with a diverse range of existing and potential supporting data sources and collectively co-learns to enable optimal diagnoses and treatment options, and new insights into disease mechanisms. Recent projects include radiogenomics, vision-language pretraining (VLP) and explainable AI for biomedical data.
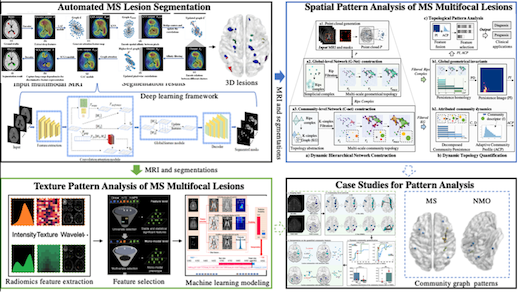
Multi-modal Image-centric Computing and Spatial-Feature Fusion for Medical Applications
Project Leader: A/Prof. Xiuying Wang
Multi-modal, multi-factorial data are becoming indispensable for modern precision medicine. We endeavour to develop synergic fusion approaches to harness multi-modal image computing and multi-factorial analytics for assisting medical applications. Our computer vision methods provide solutions to critical questions raised by high dimensionality and multimodal complexity. Based on our computational algorithms and models, we have fused important imaging features with domain factors including genomic information, biological factors for classification and prediction applications. We put emphasis on interpreting the process of decision making from machine learning models for practical applications. We developed graph models to represent the relational structure and geometric and topological patterns in interpretable learning process and for prognostic analysis. Our research focuses on dynamic topological pattern recognition through incorporating both graph structure and feature information with updating status.